Docker Desktop 4.42: llama.cpp Gets Streaming and Tool Calling Support
Docker Desktop 4.42 brings real-time streaming and tool calling to Model Runner, transforming how developers build AI applications locally. No more waiting for responses or cloud dependencies—watch AI generate content token by token with full GPU acceleration on port 12434.


Docker Desktop 4.42 brings exciting new capabilities to AI developers with enhanced llama.cpp server support in Model Runner. Two powerful features are now available that significantly improve the local AI development experience.
What's New
- Streaming Support: The llama.cpp server now delivers real-time token streaming through the OpenAI-compatible API. Instead of waiting for complete responses, you can now process AI output as it generates, creating more responsive and interactive applications.
- Tool Calling: Perhaps even more significant is the addition of tool calling capabilities. Your locally-running models can now execute functions, access external APIs, and perform complex reasoning tasks that extend beyond simple text generation.
Models That Support Tool Calling
Tool calling availability is model-specific rather than a universal Docker Model Runner feature.
Based on Docker's recent testing:
- Qwen 3 (14B) - High tool calling performance (F1 score: 0.971)
- Llama 3.3 models - Variable performance
- Some Gemma 3 variants - Limited support
Models That DON'T Support Tool Calling:
- SmolLM2 (the model used in most examples) - No tool calling capability
- Many smaller quantized models - Often lack function calling training

Why This Matters
These additions transform Docker Desktop's Model Runner from a basic inference server into a comprehensive AI development platform. Streaming enables better user experiences in chat applications, while tool calling opens doors to AI agents that can interact with databases, APIs, and external services.
The combination means you can now build sophisticated AI applications entirely locally - no cloud dependencies, better privacy, and faster iteration cycles during development.
Getting Started
With Docker Desktop 4.42, simply pull your favorite llama.cpp-compatible model and start experimenting with streaming responses and tool integrations. The familiar OpenAI API format means minimal code changes for existing applications.
Ready to upgrade your local AI development workflow? Docker Desktop 4.42 is available now.
Getting Started
Prerequisites
- Docker Desktop 4.42 or later
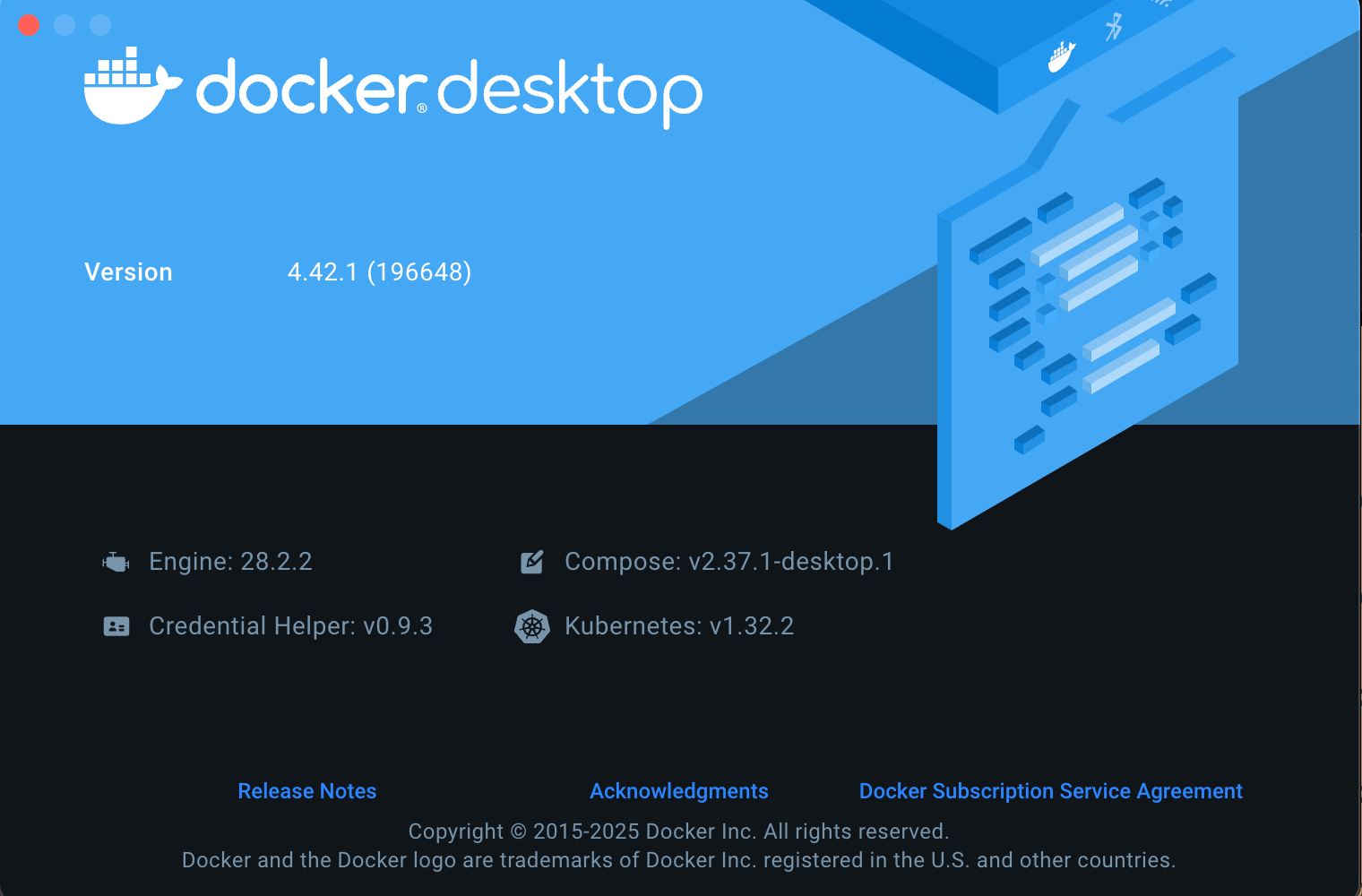
- Terminal/Command Prompt access
Step 1: Set Up Model Runner
- Open Docker Desktop 4.42
- Navigate to Model Runner (in the left sidebar)
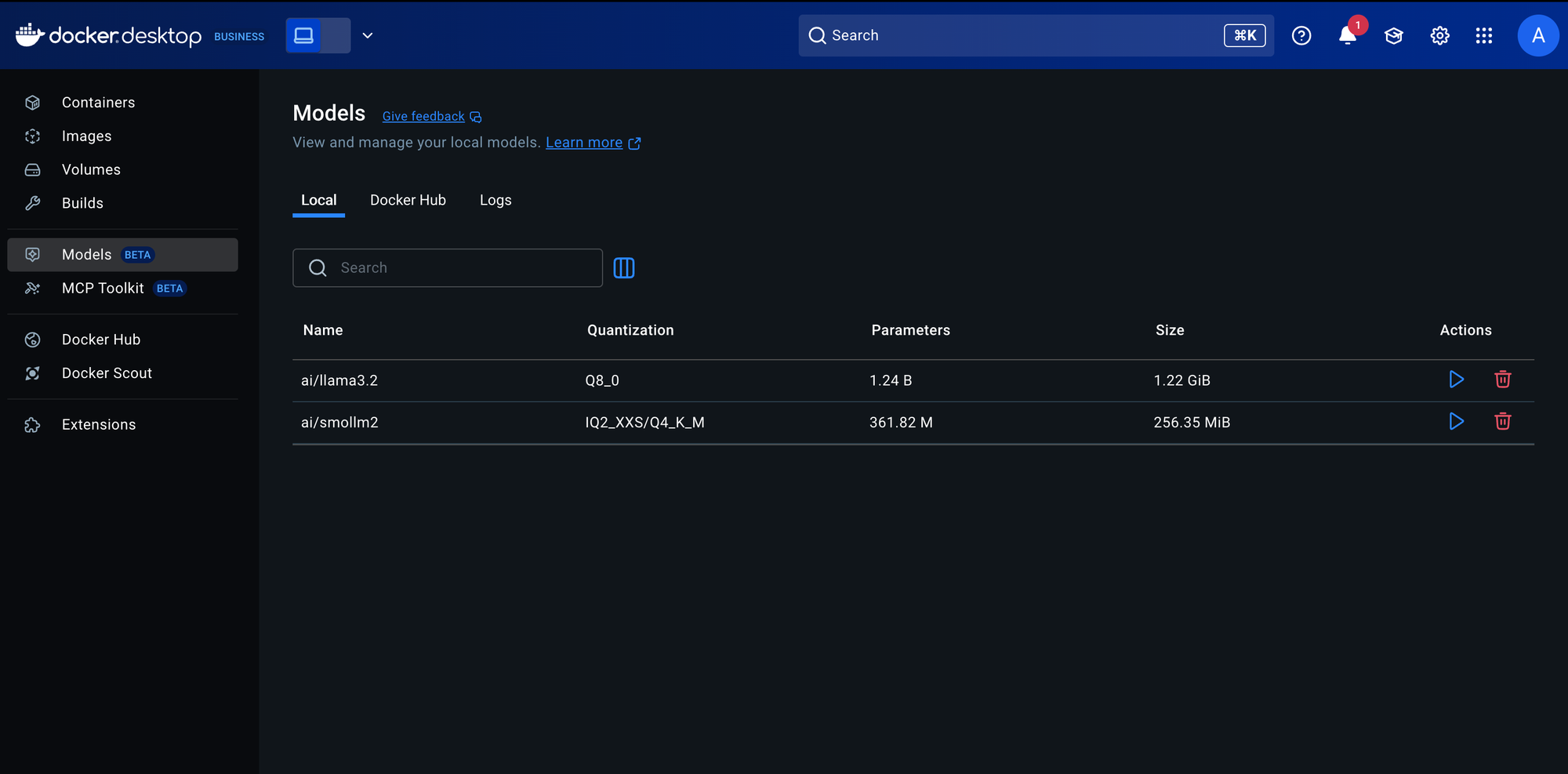
Pull a compatible model (e.g., SmolLM2 or Llama 3.2)
# Example: Pull SmolLM2
docker pull ollama/smollm2:latestStep 1: Enable Docker Model Runner
Method 1: Using CLI
# Enable Model Runner with TCP support on port 12434
docker desktop enable model-runner --tcp 12434Method 2: Using Docker Dashboard
- Open Docker Desktop
- Go to Settings → Features in development
- Enable "Docker Model Runner"
- Enable "Enable host-side TCP support" and set port to 12434
- Click "Apply & Restart"
Verify Installation
# Check if Model Runner is available
docker model --help
# Check if Model Runner is running
docker model statusStep 2: Download and Manage Models
List Available Models
# List downloaded models (initially empty)
docker model lsPull a Model from Docker Hub
# Download Llama 3.2 1B model (recommended for testing)
docker model pull ai/llama3.2:1B-Q8_0
# Other available models:
# docker model pull ai/gemma3
# docker model pull ai/qwq
# docker model pull ai/mistral-nemo
# docker model pull ai/phi4
# docker model pull ai/qwen2.5Verify Model Download
docker model ls
# Should show:
# MODEL PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
# ai/llama3.2:1B-Q8_0 1.24 B Q8_0 llama a15c3117eeeb 20 hours ago 1.22 GiBStep 3: Basic Model Testing
Quick Single Query
docker model run ai/llama3.2:1B-Q8_0 "Tell me a fun fact about dolphins"Interactive Chat Mode
docker model run ai/llama3.2:1B-Q8_0
# Interactive chat mode started. Type '/bye' to exit.
# > What is quantum computing?
# > /byeStep 4: Monitor GPU Usage (Mac Only)
- Open Activity Monitor (⌘ + Space → "Activity Monitor")
- Click "Window" → "GPU History"
- Run a query and watch GPU usage spike in real-time
- Leave Activity Monitor open for the next steps
Step 5: Demo Streaming Responses
Method 1: Direct TCP Connection (Port 12434)
curl -N http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2:1B-Q8_0",
"stream": true,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a short story about a robot learning to paint, but tell it slowly."}
]
}'Output:
data: {"choices":[{"delta":{"role":"assistant"}}],...}
data: {"choices":[{"delta":{"content":"Once"}}],...}
data: {"choices":[{"delta":{"content":" upon"}}],...}
data: {"choices":[{"delta":{"content":" a"}}],...}
...Method 2: Python Streaming Client
import requests
import json
def stream_response():
url = "http://localhost:12434/engines/llama.cpp/v1/chat/completions"
data = {
"model": "ai/llama3.2:1B-Q8_0",
"stream": True,
"messages": [
{"role": "user", "content": "Tell me about the history of computers"}
]
}
print("🤖 AI Response (streaming):")
response = requests.post(url, json=data, stream=True)
for line in response.iter_lines():
if line and line.startswith(b'data: '):
try:
chunk = json.loads(line[6:])
if 'choices' in chunk and chunk['choices']:
delta = chunk['choices'][0].get('delta', {})
if 'content' in delta:
print(delta['content'], end='', flush=True)
except json.JSONDecodeError:
continue
print("\n✅ Stream completed!")
# Run the demo
stream_response()Copy the above content and save it in a file called stream.py
Execute the python code.
pip install requests
python3 stream.pyWhat the code does:
- Connects to a local llama.cpp server on port 12434
- Sends a chat completion request with streaming enabled
- Parses the Server-Sent Events (SSE) response format
- Prints the AI response in real-time as it streams
Step 6: Demo Tool Calling
Simple Tool Calling Test
curl -N http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2:1B-Q8_0",
"stream": true,
"messages": [
{"role": "user", "content": "What is the weather like in San Francisco? Use the weather tool."}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name"
},
"units": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Temperature units"
}
},
"required": ["location"]
}
}
}
]
}'What this curl command does:
- Streams a chat completion with tool definitions
- Defines a weather function that the AI can potentially call
- Asks the AI to use the weather tool explicitly
- Tests function calling capabilities of your local model
In nutshell, this curl command is testing function calling (tool use) with your local LLM server! This is more advanced than basic streaming - it's testing whether your model can understand and call external tools.
Advanced Tool Calling with Python
import requests
import json
def demo_tool_calling():
url = "http://localhost:12434/engines/llama.cpp/v1/chat/completions"
tools = [
{
"type": "function",
"function": {
"name": "calculate",
"description": "Perform mathematical calculations",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "Math expression to evaluate"
}
},
"required": ["expression"]
}
}
},
{
"type": "function",
"function": {
"name": "search_web",
"description": "Search the web for information",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search query"
}
},
"required": ["query"]
}
}
}
]
data = {
"model": "ai/llama3.2:1B-Q8_0",
"stream": True,
"messages": [
{
"role": "user",
"content": "Calculate 25 * 17 + 89 and then search for information about Docker containers"
}
],
"tools": tools
}
print("🔧 Testing Tool Calling...")
response = requests.post(url, json=data, stream=True)
for line in response.iter_lines():
if line and line.startswith(b'data: '):
try:
chunk = json.loads(line[6:])
if 'choices' in chunk and chunk['choices']:
choice = chunk['choices'][0]
# Handle regular content
if 'delta' in choice and 'content' in choice['delta']:
print(choice['delta']['content'], end='', flush=True)
# Handle tool calls
if 'delta' in choice and 'tool_calls' in choice['delta']:
tool_calls = choice['delta']['tool_calls']
for tool_call in tool_calls:
print(f"\n🔧 Tool Call Detected: {tool_call}")
except json.JSONDecodeError:
continue
demo_tool_calling()This code tests function calling (also known as tool use) capabilities of a local LLM server. It defines two tools that the AI can potentially use: a calculate function for math operations and a search_web function for web searches. The code then sends a compound request asking the AI to "Calculate 25 * 17 + 89 and then search for information about Docker containers" - deliberately requiring both tools to complete the task properly.
The code streams the AI's response and monitors for two types of output: regular text content and structured tool calls. If the model supports function calling, it should recognize that the user's request requires mathematical calculation and web searching, then respond with properly formatted JSON function calls containing the function names and appropriate parameters (like {"expression": "25 * 17 + 89"} for the calculator).
Wrapping Up
With Docker Desktop 4.42, simply pull your favorite llama.cpp-compatible model and start experimenting with streaming responses and tool integrations. The familiar OpenAI API format means minimal code changes for existing applications.
Ready to upgrade your local AI development workflow? Docker Desktop 4.42 is available now.