What is Docker Model Runner and what problem does it solve?
A GPU-accelerated LLM runner that enables developers to run AI models locally

Docker Model Runner is a new experimental feature introduced in Docker Desktop for Mac 4.40+ that provides a Docker-native experience for running Large Language Models (LLMs) locally. It seamlessly integrates with existing container tooling and workflows, bringing AI capabilities directly into the Docker ecosystem.
What's unique about Docker Model Runner?
Unlike traditional Docker containers that package large AI models with the model runtime (which results in slow deployment), Model Runner separates the model from the runtime, allowing for faster deployment.
What does it mean? Let's understand this in detail.
Traditional Docker images in Docker Hub are stored in compressed format, and when you run docker pull, the image gets uncompressed on your local disk, often doubling your storage requirement.
AI models work fundamentally differently because they consist of mathematical weights - essentially numbers that don't benefit from compression. When you use docker model pull, the model files don't undergo compression or decompression because compressing numerical weights provides minimal benefit and can actually slow down the process.
This means no compression overhead during download, no duplicate storage of compressed and uncompressed versions, faster model loading and deployment, and significantly more efficient disk usage overall.
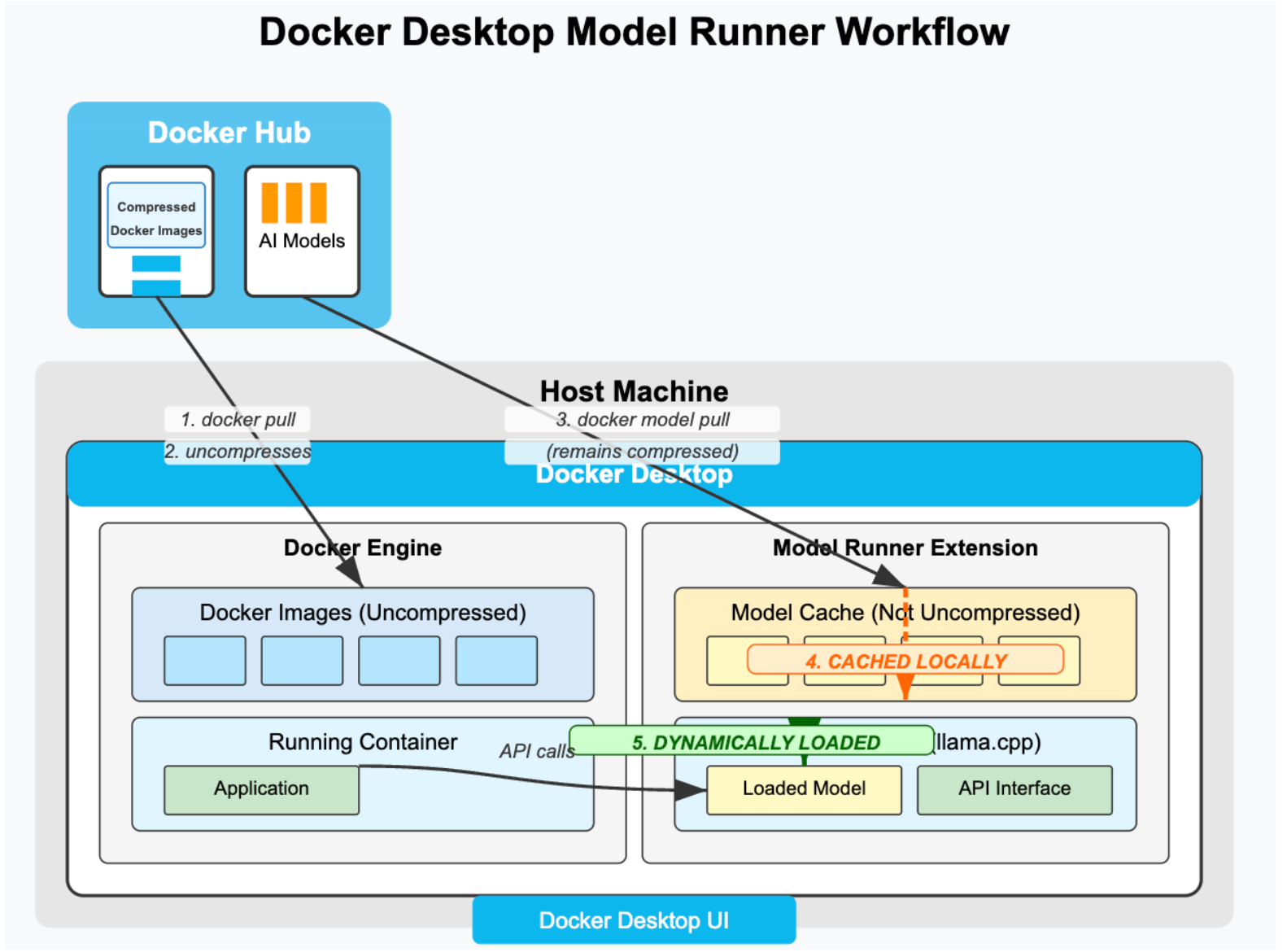
Model Runner enables local LLM execution. It runs large language models (LLMs) directly on your machine rather than sending data to external API services. This means your data never leaves your infrastructure. All you need to do is pull the model from Docker Hub and start integrating it with your application.
Architecture of Docker Model Runner
Docker Model Runner implements a unique hybrid approach that combines Docker's orchestration capabilities with native host performance for AI inference. Let me break down the key architectural components and explain how they work together:
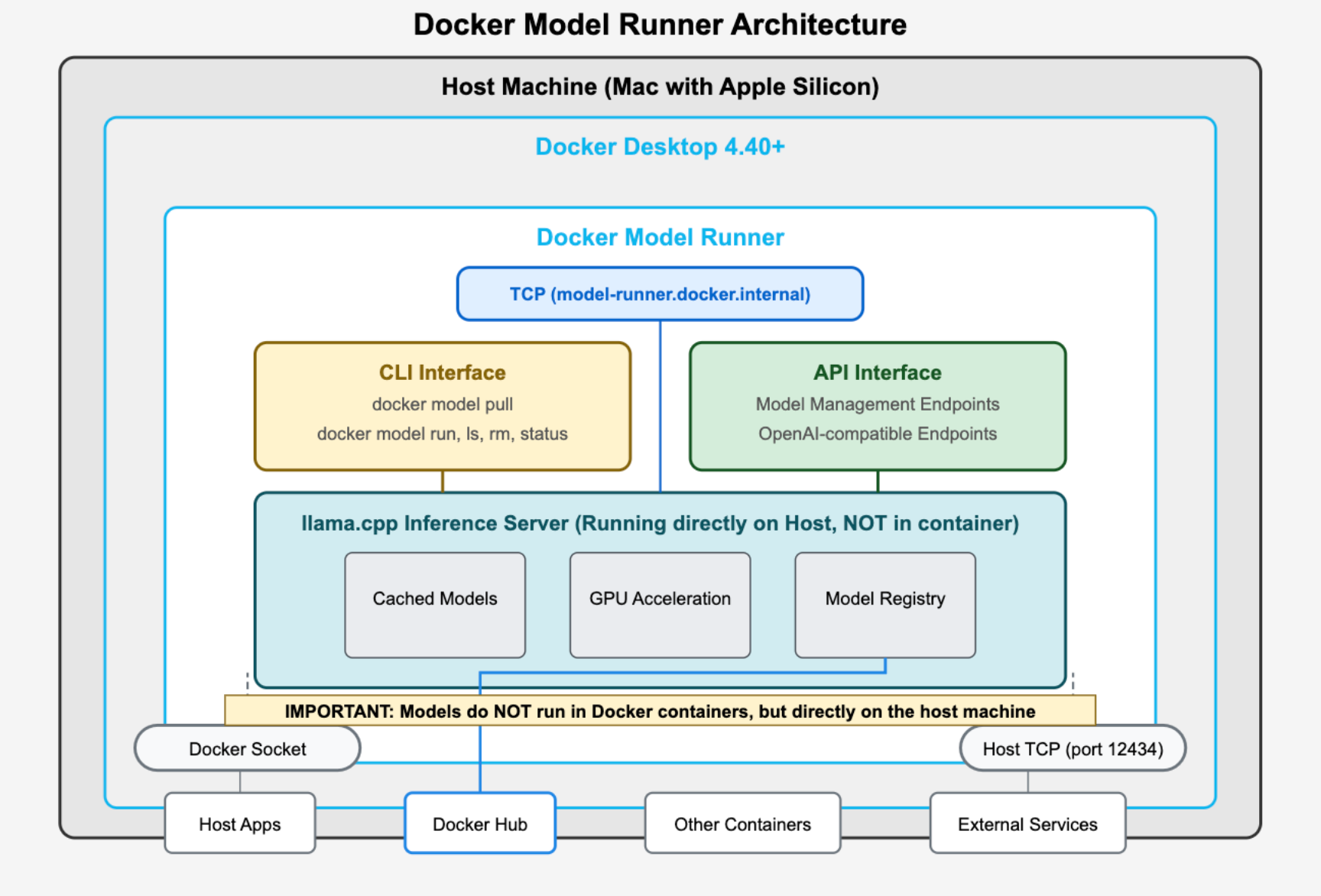
Core Architecture Components
Host Machine Layer (Mac with Apple Silicon) The entire system runs on Apple Silicon Macs, taking advantage of the Metal API for GPU acceleration. This is the foundation that enables the performance benefits.
Docker Desktop 4.40+ Container Docker Desktop provides the management layer and orchestration, but importantly, it doesn't containerize the actual AI inference workload. Instead, it manages the lifecycle and provides interfaces.
llama.cpp Inference Server (Host-Native) This is the critical architectural decision - the inference server runs directly on the host machine, NOT inside a Docker container. This design choice enables:
- Direct access to Apple's Metal API for GPU acceleration
- Elimination of containerization overhead for compute-intensive operations
- Native performance for model inference
Two-Tier Interface System
CLI Interface The docker model commands (pull, run, ls, rm, status) provide a familiar Docker-like experience for model management. This maintains consistency with existing Docker workflows while introducing AI-specific operations.
API Interface Offers two types of endpoints:
- Model Management Endpoints: For administrative operations (listing, pulling, removing models)
- OpenAI-compatible Endpoints: For inference requests, ensuring seamless integration with existing AI applications
Dual Connection Architecture
The diagram shows two primary connection methods, each serving different use cases:
1. Docker Socket Connection (/var/run/docker.sock)
- Used by host applications and containers within the Docker network
- Enables internal communication between Docker components
- Connects to Docker Hub for model downloads
- Ideal for containerized applications that need to access models
2. Host TCP Connection (port 12434)
- Provides direct network access from external services
- Allows non-containerized applications to connect
- Enables integration with services outside the Docker ecosystem
- Accessible via
model-runner.docker.internalfrom containers orlocalhost:12434from the host
Model Storage and Execution Flow
Model Registry and Caching
- Models are downloaded from Docker Hub as OCI artifacts
- Cached locally on the host machine for quick access
- The Model Registry tracks available and loaded models
- No compression/decompression overhead during model loading
GPU Acceleration Pipeline
- Direct access to Apple Silicon's integrated GPU
- Utilizes Metal API for optimized inference performance
- No virtualization layer between the inference engine and hardware
- Real-time GPU utilization visible in Activity Monitor
Key Architectural Benefits
Performance Optimization By running the inference server directly on the host, the architecture eliminates the performance penalty of containerization for compute-intensive AI workloads while maintaining Docker's benefits for orchestration and management.
Flexibility in Integration The dual connection approach allows both containerized and non-containerized applications to access the same models, providing maximum flexibility for different deployment scenarios.
Resource Efficiency Models are shared across all applications accessing the Model Runner, avoiding duplication and reducing memory footprint compared to running separate containerized inference servers.
Developer Experience The familiar Docker CLI interface combined with OpenAI-compatible APIs means developers can integrate AI capabilities without learning new tools or significantly changing their existing workflows.
This architecture represents a thoughtful balance between Docker's container orchestration strengths and the performance requirements of AI inference workloads, creating a system that's both powerful and accessible to developers already familiar with Docker ecosystems.
Let's see it in action.
Getting Started with Model Runner
Prerequisites
- macOS with Apple Silicon (M1/M2/M3/M4) - Windows support coming soon
- Docker Desktop 4.40+
- Python 3.8+ installed on your system
- Basic familiarity with Python and Docker
Step 1: Install and Configure Docker Desktop
1.1 Download Docker Desktop 4.40+
Download the latest version from Docker's official website.
1.2 Enable Docker Model Runner
Option A: Using CLI
docker desktop enable model-runnerOption B: Using Docker Dashboard
- Open Docker Desktop
- Go to Settings → Features in development
- Enable "Docker Model Runner"
- Optionally enable "Enable host-side TCP support" and set port (default: 12434)
- Click "Apply & Restart"
1.3 Verify Installation
docker model --help
docker model statusExpected output:
Docker Model Runner is runningStep 2: Download an AI Model
2.1 List Available Models
docker model ls2.2 Pull a Model from Docker Hub
docker model pull ai/llama3.2:1B-Q8_02.3 Verify Model Download
docker model lsExpected output:
MODEL PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/llama3.2:1B-Q8_0 1.24 B Q8_0 llama a15c3117eeeb 20 hours ago 1.22 GiBStep 3: Set Up Python Environment
3.1 Create a Project Directory
mkdir docker-model-runner-python
cd docker-model-runner-python3.2 Create a Virtual Environment
python -m venv venv
source venv/bin/activate # On macOS/Linux
# or
# venv\Scripts\activate # On Windows3.3 Install Required Python Packages
pip install openai requests python-dotenv3.4 Create Requirements File
pip freeze > requirements.txtStep 4: Basic Python Integration
4.1 Create a Simple Chat Script
Create basic_chat.py:
import requests
import json
def chat_with_model(message, model="ai/llama3.2:1B-Q8_0"):
"""
Send a chat message to Docker Model Runner using direct HTTP requests
"""
url = "http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions"
payload = {
"model": model,
"messages": [
{"role": "user", "content": message}
],
"max_tokens": 100,
"temperature": 0.7
}
headers = {
"Content-Type": "application/json"
}
try:
response = requests.post(url, json=payload, headers=headers)
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"]
except requests.exceptions.RequestException as e:
return f"Error: {e}"
if __name__ == "__main__":
message = input("Enter your message: ")
response = chat_with_model(message)
print(f"AI Response: {response}")4.2 Test the Basic Script
python basic_chat.pyStep 5: Using OpenAI Python Client
5.1 Create OpenAI-Compatible Client
Create openai_client.py:
from openai import OpenAI
import os
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
class DockerModelRunner:
def __init__(self, base_url="http://model-runner.docker.internal/engines/llama.cpp/v1/"):
"""
Initialize Docker Model Runner client using OpenAI SDK
"""
self.client = OpenAI(
base_url=base_url,
api_key="docker-model-runner" # Dummy key, required by OpenAI client
)
self.model = os.getenv("MODEL", "ai/llama3.2:1B-Q8_0")
def chat(self, message, system_message=None):
"""
Send a chat completion request
"""
messages = []
if system_message:
messages.append({"role": "system", "content": system_message})
messages.append({"role": "user", "content": message})
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
max_tokens=150,
temperature=0.7
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {e}"
def stream_chat(self, message):
"""
Stream chat responses
"""
try:
stream = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=150,
temperature=0.7,
stream=True
)
response_text = ""
for chunk in stream:
if chunk.choices[0].delta.content is not None:
content = chunk.choices[0].delta.content
response_text += content
print(content, end="", flush=True)
print() # New line after streaming
return response_text
except Exception as e:
return f"Error: {e}"
if __name__ == "__main__":
runner = DockerModelRunner()
print("Docker Model Runner Chat (type 'quit' to exit)")
print("-" * 50)
while True:
user_input = input("\nYou: ")
if user_input.lower() in ['quit', 'exit', 'bye']:
print("Goodbye!")
break
print("AI: ", end="")
runner.stream_chat(user_input)5.2 Create Environment File
Create .env:
MODEL=ai/llama3.2:1B-Q8_0
BASE_URL=http://model-runner.docker.internal/engines/llama.cpp/v1/5.3 Test OpenAI Client
python openai_client.pyStep 6: Advanced Python Integration
6.1 Create a Flask Web Application
Create app.py:
from flask import Flask, request, jsonify, render_template_string
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
app = Flask(__name__)
# Initialize OpenAI client for Docker Model Runner
client = OpenAI(
base_url=os.getenv("BASE_URL", "http://model-runner.docker.internal/engines/llama.cpp/v1/"),
api_key="docker-model-runner"
)
MODEL = os.getenv("MODEL", "ai/llama3.2:1B-Q8_0")
@app.route('/')
def index():
return render_template_string("""
<!DOCTYPE html>
<html>
<head>
<title>Docker Model Runner Chat</title>
<style>
body { font-family: Arial, sans-serif; max-width: 800px; margin: 50px auto; padding: 20px; }
.chat-container { border: 1px solid #ddd; height: 400px; overflow-y: scroll; padding: 10px; margin-bottom: 20px; }
.message { margin: 10px 0; padding: 10px; border-radius: 5px; }
.user { background-color: #e3f2fd; text-align: right; }
.ai { background-color: #f5f5f5; }
input[type="text"] { width: 70%; padding: 10px; }
button { padding: 10px 20px; }
</style>
</head>
<body>
<h1>Docker Model Runner Chat</h1>
<div id="chat-container" class="chat-container"></div>
<input type="text" id="message-input" placeholder="Type your message..." onkeypress="if(event.key==='Enter') sendMessage()">
<button onclick="sendMessage()">Send</button>
<script>
async function sendMessage() {
const input = document.getElementById('message-input');
const message = input.value.trim();
if (!message) return;
addMessage('You', message, 'user');
input.value = '';
try {
const response = await fetch('/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message })
});
const data = await response.json();
addMessage('AI', data.response, 'ai');
} catch (error) {
addMessage('Error', 'Failed to get response', 'ai');
}
}
function addMessage(sender, text, className) {
const container = document.getElementById('chat-container');
const div = document.createElement('div');
div.className = `message ${className}`;
div.innerHTML = `<strong>${sender}:</strong> ${text}`;
container.appendChild(div);
container.scrollTop = container.scrollHeight;
}
</script>
</body>
</html>
""")
@app.route('/chat', methods=['POST'])
def chat():
data = request.json
message = data.get('message', '')
try:
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": message}],
max_tokens=150,
temperature=0.7
)
ai_response = response.choices[0].message.content
return jsonify({"response": ai_response})
except Exception as e:
return jsonify({"response": f"Error: {str(e)}"}), 500
if __name__ == '__main__':
app.run(debug=True, port=5000)6.2 Install Flask
pip install flask6.3 Run the Flask Application
python app.pyVisit http://localhost:5000 in your browser.
Step 7: Using TCP Host Support (Alternative Connection Method)
7.1 Enable TCP Support
Using CLI:
docker desktop enable model-runner --tcp 12434Or via Docker Dashboard: Enable "Enable host-side TCP support" and set port to 12434.
7.2 Create TCP Client Script
Create tcp_client.py:
from openai import OpenAI
import os
class DockerModelRunnerTCP:
def __init__(self, host="localhost", port=12434):
"""
Connect to Docker Model Runner via TCP
"""
base_url = f"http://{host}:{port}/engines/llama.cpp/v1/"
self.client = OpenAI(
base_url=base_url,
api_key="docker-model-runner"
)
self.model = "ai/llama3.2:1B-Q8_0"
def chat(self, message):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=100,
temperature=0.7
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {e}"
if __name__ == "__main__":
runner = DockerModelRunnerTCP()
message = input("Enter your message: ")
response = runner.chat(message)
print(f"AI Response: {response}")Step 8: Error Handling and Best Practices
8.1 Create Robust Client with Error Handling
Create robust_client.py:
import time
import logging
from openai import OpenAI
from typing import Optional, Generator
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class DockerModelRunnerClient:
def __init__(self, base_url: str = "http://model-runner.docker.internal/engines/llama.cpp/v1/",
model: str = "ai/llama3.2:1B-Q8_0",
max_retries: int = 3,
retry_delay: float = 1.0):
self.client = OpenAI(base_url=base_url, api_key="dummy")
self.model = model
self.max_retries = max_retries
self.retry_delay = retry_delay
def _make_request_with_retry(self, request_func, *args, **kwargs):
"""Make request with retry logic"""
last_exception = None
for attempt in range(self.max_retries):
try:
return request_func(*args, **kwargs)
except Exception as e:
last_exception = e
logger.warning(f"Attempt {attempt + 1} failed: {e}")
if attempt < self.max_retries - 1:
time.sleep(self.retry_delay * (2 ** attempt)) # Exponential backoff
raise last_exception
def chat(self, message: str, system_message: Optional[str] = None,
max_tokens: int = 150, temperature: float = 0.7) -> str:
"""Send chat completion request with retry logic"""
messages = []
if system_message:
messages.append({"role": "system", "content": system_message})
messages.append({"role": "user", "content": message})
def make_request():
return self.client.chat.completions.create(
model=self.model,
messages=messages,
max_tokens=max_tokens,
temperature=temperature
)
try:
response = self._make_request_with_retry(make_request)
return response.choices[0].message.content
except Exception as e:
logger.error(f"Failed to get response after {self.max_retries} attempts: {e}")
return f"Error: Unable to get response from model"
def check_model_status(self) -> bool:
"""Check if the model is available"""
try:
models = self.client.models.list()
available_models = [model.id for model in models.data]
return self.model in available_models
except Exception as e:
logger.error(f"Failed to check model status: {e}")
return False
# Usage example
if __name__ == "__main__":
client = DockerModelRunnerClient()
# Check if model is available
if client.check_model_status():
print("✅ Model is available")
else:
print("❌ Model is not available")
# Test chat
response = client.chat("Hello, how are you?")
print(f"Response: {response}")Step 9: Testing and Validation
9.1 Create Test Script
Create test_model_runner.py:
import unittest
from robust_client import DockerModelRunnerClient
class TestDockerModelRunner(unittest.TestCase):
def setUp(self):
self.client = DockerModelRunnerClient()
def test_model_availability(self):
"""Test if model is available"""
self.assertTrue(self.client.check_model_status(), "Model should be available")
def test_basic_chat(self):
"""Test basic chat functionality"""
response = self.client.chat("Say hello")
self.assertIsInstance(response, str)
self.assertGreater(len(response), 0)
def test_system_message(self):
"""Test chat with system message"""
response = self.client.chat(
"What's your role?",
system_message="You are a helpful assistant."
)
self.assertIsInstance(response, str)
self.assertGreater(len(response), 0)
if __name__ == "__main__":
unittest.main()9.2 Run Tests
python test_model_runner.pyTroubleshooting
Common Issues and Solutions
- Connection Refused Error
- Ensure Docker Desktop is running
- Verify Model Runner is enabled:
docker model status - Check if the model is downloaded:
docker model ls
- Model Not Found Error
- Pull the model:
docker model pull ai/llama3.2:1B-Q8_0 - Verify model name matches exactly
- Pull the model:
- Slow Response Times
- Check GPU usage in Activity Monitor
- Consider using a smaller model for testing
- Ensure sufficient system memory
- TCP Connection Issues
- Verify TCP support is enabled in Docker Desktop
- Check port 12434 is not used by other applications
- Use
host.docker.internalinstead oflocalhostin containers
Checking Logs
tail -f ~/Library/Containers/com.docker.docker/Data/log/host/inference-llama.cpp.logNext Steps
- Experiment with different models available in the Docker Hub
ai/namespace - Build more complex applications using conversation history
- Integrate with other Python frameworks like Django or FastAPI
- Explore embeddings and other OpenAI-compatible endpoints
- Consider building production applications with proper error handling and monitoring