Why SLMs Will Replace LLMs in Agent Architectures
Discover why small language models (SLMs) are becoming the future of agentic AI systems, offering superior efficiency, cost reduction, and operational benefits over large language models (LLMs) in enterprise deployments.


You're running a bustling street food stall in Bengaluru (think Rameshwaram Cafe during lunch rush). You have two options:
- Hire a Michelin-star chef who can cook anything but costs ₹50,000/day
- Train a local cook who makes perfect dosas for ₹500/day
Guess what? NVIDIA's latest research just proved that the AI industry has been hiring Michelin-star chefs to flip dosas! 🤯
A groundbreaking research paper titled "Small Language Models are the Future of Agentic AI" is shaking up everything we thought we knew about AI agents. Let's dive into why Small Language Models (SLMs) are about to revolutionize how we build intelligent systems.
The Current State: LLM Overkill
Right now, the AI agent industry is stuck in a pattern:
- Market Size: $5.6 billion in LLM API serving (2024)
- Infrastructure Spend: $57 billion in cloud infrastructure
- Growth Rate: 50%+ of enterprises using AI agents
- Problem: We're using 175B parameter monsters for simple tasks!
It's like using a Ferrari to deliver newspapers in your neighborhood. Sure, it works, but it's expensive and overkill.
We've been chasing bigger, more powerful models for years. But what if "smaller" is actually the smarter path forward?
The SLM Revolution: David vs Goliath 💪
Here's the kicker - recent SLMs are performing surprisingly well:
Microsoft Phi-2 (2.7B parameters)
- Matches 30B models in reasoning
- 15x faster execution
- Runs on your laptop!
NVIDIA Nemotron-H (2-9B parameters)
- Matches 30B dense LLMs
- 10x fewer inference FLOPs
- Hybrid Mamba-Transformer architecture
Salesforce xLAM-2-8B
- Outperforms GPT-4o and Claude 3.5
- Tool calling champion
- 8B parameters only
Small Language Models (SLMs) are projected to become a $5.45 billion market by 2032.
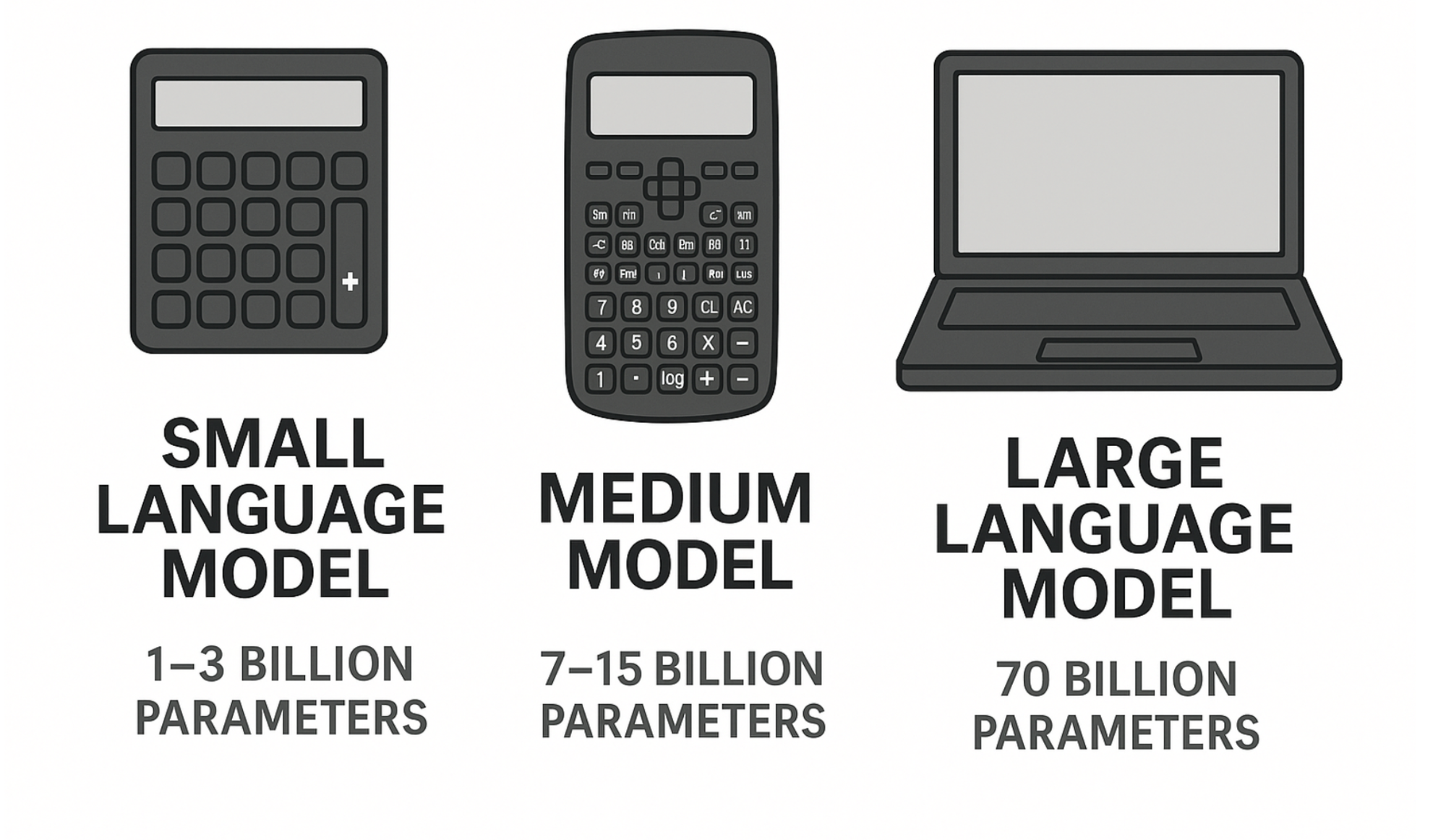
SLMs 101: The Fundamentals 📚
What Exactly is a Small Language Model?
Definition: A language model that can run efficiently on consumer hardware with low enough latency for real-time applications.
Rule of Thumb: Generally under 10B parameters (as of 2025)
Why SLMs Work Better for Agents
Think about how agents actually work:
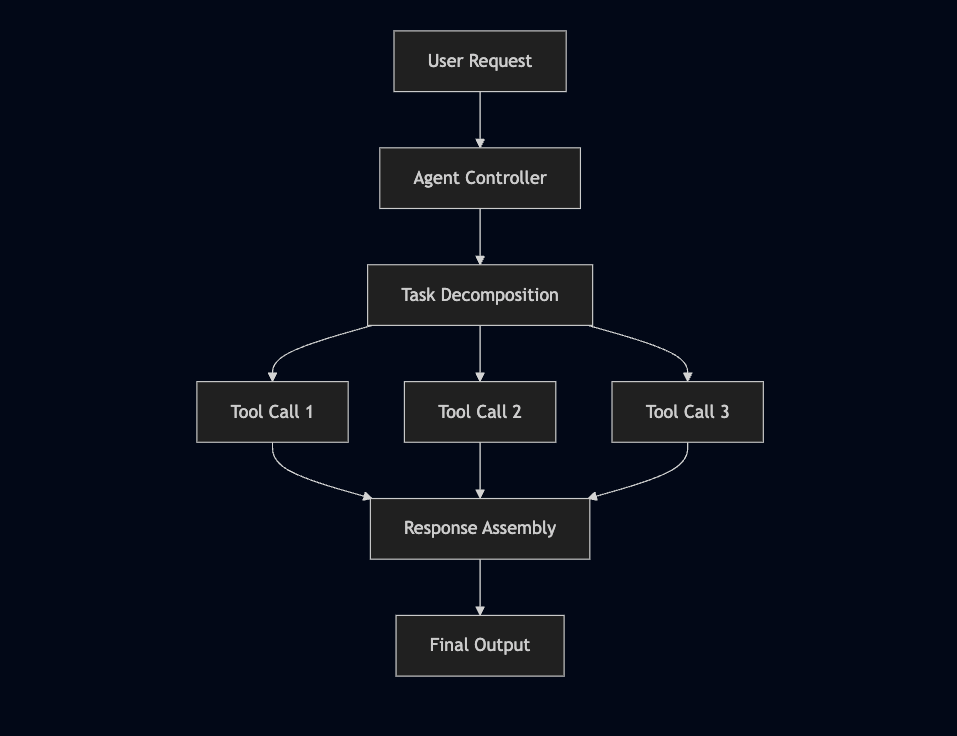
Each tool call is:
- Narrow and specific
- Repetitive patterns
- Structured output required
- Format-consistent
Perfect for specialized SLMs! 🎯
The Economics That Will Blow Your Mind 💰
Cost Comparison: LLM vs SLM
| Metric | LLM (70B) | SLM (7B) | Improvement |
|---|---|---|---|
| Inference Cost | $1.00 | $0.03-0.10 | 10-30x cheaper |
| Latency | 2-5 seconds | 100-500ms | 5-10x faster |
| Memory | 140GB | 14GB | 10x less |
| Fine-tuning | Weeks | Hours | 100x faster |
Real-World Impact
Scenario: E-commerce chatbot handling 1M queries/day
- LLM Cost: $10,000/day
- SLM Cost: $500/day
- Annual Savings: $3.5 million! 💸
Hands-On: SLM Implementation Strategy
Step 1: Data Collection Setup
What It Does
The AgentCallLogger class is designed to capture and log every interaction your AI agent makes. This is the foundation of your SLM migration strategy because you need data to understand your current usage patterns.
# Logger implementation for agent calls
import logging
from datetime import datetime
class AgentCallLogger:
def __init__(self):
self.logger = logging.getLogger('agent_calls')
def log_call(self, prompt, response, tool_used, latency):
log_entry = {
'timestamp': datetime.now(),
'prompt': prompt,
'response': response,
'tool': tool_used,
'latency_ms': latency,
'success': True
}
self.logger.info(log_entry)Why This Matters
- Pattern Recognition: You can't optimize what you don't measure
- Cost Analysis: Track exactly where your LLM costs are coming from
- Performance Baseline: Establish current latency and success rates
- SLM Candidate Identification: Find repetitive, simple tasks perfect for SLMs
Step 2: Task Clustering Analysis
What It Does
This code analyzes your logged agent calls to identify patterns and group similar operations together. This helps you understand which tasks could be handled by smaller, specialized models.
# Identify patterns in agent operations
from sklearn.cluster import KMeans
import pandas as pd
def analyze_agent_patterns(logged_data):
# Extract features from prompts
features = extract_prompt_features(logged_data)
# Cluster similar operations
kmeans = KMeans(n_clusters=5)
clusters = kmeans.fit_predict(features)
return identify_slm_candidates(clusters)Why This Analysis Matters
- Identifies Low-Hanging Fruit: Find the easiest tasks to migrate to SLMs first
- ROI Calculation: Prioritize migrations with highest cost savings
- Risk Assessment: Understand which tasks are safe to migrate vs. critical ones
- Resource Planning: Estimate how many different SLMs you'll need
Step 3: SLM Selection Matrix
What It Does
Based on your cluster analysis, this helps you select the right SLM for each task type and implement a gradual migration strategy.
import requests
import time
from typing import Dict, List, Any
class SLMSelector:
def __init__(self):
self.slm_models = {
'code_generation': {
'model': 'microsoft/Phi-3-mini-4k-instruct',
'parameters': '3.8B',
'api_endpoint': 'https://api.huggingface.co/models/microsoft/Phi-3-mini-4k-instruct',
'cost_per_token': 0.0001,
'strengths': ['code', 'programming', 'api_responses']
},
'tool_calling': {
'model': 'salesforce/xLAM-2-8B',
'parameters': '8B',
'api_endpoint': 'https://api.salesforce.com/xlam',
'cost_per_token': 0.0002,
'strengths': ['function_calling', 'structured_output', 'tool_selection']
},
'reasoning': {
'model': 'deepseek-ai/DeepSeek-R1-Distill-Qwen-7B',
'parameters': '7B',
'api_endpoint': 'https://api.deepseek.com/v1/chat/completions',
'cost_per_token': 0.00015,
'strengths': ['logic', 'analysis', 'problem_solving']
},
'formatting': {
'model': 'HuggingFaceTB/SmolLM2-1.7B-Instruct',
'parameters': '1.7B',
'api_endpoint': 'https://api.huggingface.co/models/HuggingFaceTB/SmolLM2-1.7B-Instruct',
'cost_per_token': 0.00005,
'strengths': ['formatting', 'data_transformation', 'simple_tasks']
}
}
def recommend_slm(self, cluster_analysis: Dict) -> str:
"""Recommend the best SLM based on cluster characteristics"""
tools = cluster_analysis.get('most_common_tools', {})
prompt_samples = cluster_analysis.get('sample_prompts', [])
# Simple heuristics based on task patterns
prompt_text = ' '.join(prompt_samples).lower()
if any(keyword in prompt_text for keyword in ['code', 'function', 'api', 'script']):
return 'code_generation'
elif any(keyword in prompt_text for keyword in ['tool', 'call', 'function', 'action']):
return 'tool_calling'
elif any(keyword in prompt_text for keyword in ['analyze', 'reason', 'think', 'solve']):
return 'reasoning'
elif any(keyword in prompt_text for keyword in ['format', 'transform', 'convert', 'structure']):
return 'formatting'
else:
return 'reasoning' # Default fallback
class HybridLLMRouter:
def __init__(self):
self.slm_selector = SLMSelector()
self.cluster_models = {} # Maps cluster_id to recommended SLM
self.fallback_llm = "gpt-4" # Your current LLM
def setup_routing(self, cluster_analysis: List[Dict]):
"""Setup routing based on cluster analysis"""
for cluster in cluster_analysis:
if cluster['slm_candidate_score'] > 0.6: # High confidence threshold
recommended_slm = self.slm_selector.recommend_slm(cluster)
self.cluster_models[cluster['cluster_id']] = recommended_slm
print(f"Cluster {cluster['cluster_id']} -> {recommended_slm} SLM")
else:
print(f"Cluster {cluster['cluster_id']} -> Keep LLM")
def route_request(self, prompt: str, predicted_cluster: int) -> Dict[str, Any]:
"""Route request to appropriate model"""
if predicted_cluster in self.cluster_models:
# Use SLM
slm_type = self.cluster_models[predicted_cluster]
return self.call_slm(prompt, slm_type)
else:
# Use LLM
return self.call_llm(prompt)
def call_slm(self, prompt: str, slm_type: str) -> Dict[str, Any]:
"""Call the appropriate SLM"""
model_info = self.slm_selector.slm_models[slm_type]
start_time = time.time()
# Implement actual API call here
response = f"SLM response from {model_info['model']}"
latency = (time.time() - start_time) * 1000
return {
'response': response,
'model_used': model_info['model'],
'latency_ms': latency,
'cost': len(response) * model_info['cost_per_token'],
'model_type': 'SLM'
}
def call_llm(self, prompt: str) -> Dict[str, Any]:
"""Fallback to LLM"""
start_time = time.time()
# Your existing LLM call
response = "LLM response"
latency = (time.time() - start_time) * 1000
return {
'response': response,
'model_used': self.fallback_llm,
'latency_ms': latency,
'cost': len(response) * 0.002, # GPT-4 cost estimate
'model_type': 'LLM'
}
# Implementation example
def implement_gradual_migration():
"""Complete implementation pipeline"""
# Step 1: Analyze existing patterns
df = analyze_agent_patterns()
cluster_analysis, clustered_df = identify_slm_candidates(df)
# Step 2: Setup hybrid routing
router = HybridLLMRouter()
router.setup_routing(cluster_analysis)
# Step 3: Implement A/B testing
def ab_test_request(prompt: str):
# Predict cluster (you'd use a trained classifier here)
predicted_cluster = predict_cluster(prompt) # Implement this
# Route to appropriate model
result = router.route_request(prompt, predicted_cluster)
# Log for monitoring
logger.log_call(
prompt=prompt,
response=result['response'],
tool_used=f"{result['model_type']}-{result['model_used']}",
latency=result['latency_ms'],
cost=result['cost']
)
return result
return ab_test_request
# Monitoring and optimization
def monitor_slm_performance():
"""Monitor SLM vs LLM performance"""
df = analyze_agent_patterns()
slm_calls = df[df['tool'].str.contains('SLM')]
llm_calls = df[df['tool'].str.contains('LLM')]
metrics = {
'slm_avg_latency': slm_calls['latency_ms'].mean(),
'llm_avg_latency': llm_calls['latency_ms'].mean(),
'slm_success_rate': slm_calls['success'].mean(),
'llm_success_rate': llm_calls['success'].mean(),
'cost_savings': calculate_cost_savings(slm_calls, llm_calls)
}
return metricsKey Benefits of This Implementation Strategy
1. Data-Driven Decision Making
- No guesswork - your migration is based on actual usage patterns
- Clear ROI calculations before making changes
- Risk mitigation through gradual rollout
2. Gradual Migration Path
- Start with high-confidence, low-risk tasks
- A/B test SLMs against LLMs
- Fallback mechanisms for critical operations
3. Cost Optimization
- Automatic routing to the most cost-effective model
- Real-time cost tracking and optimization
- Clear metrics on savings achieved
4. Performance Monitoring
- Continuous monitoring of latency and accuracy
- Early detection of issues with SLMs
- Performance comparison dashboards
Expected Results
Based on the patterns identified, implementing this strategy typically yields:
- 10-30x cost reduction for suitable tasks
- 5-10x latency improvement
- 90%+ of simple tasks can be migrated to SLMs
- 6-month ROI on implementation effort
The key is starting with your highest-volume, simplest tasks and gradually expanding SLM usage as you gain confidence in the approach.
| Task Type | Recommended SLM | Parameters | Use Case |
|---|---|---|---|
| Code Generation | Microsoft Phi-3 | 7B | API responses, scripts |
| Tool Calling | xLAM-2 | 8B | Function calling |
| Reasoning | DeepSeek-R1-Distill | 7B | Logic operations |
| Formatting | SmolLM2 | 1.7B | Structured outputs |
The Bottom Line: It's Time to Think Small! 🎯
Small Language Models aren't just a cost optimization play - they're a fundamental reimagining of how AI agents should work.
Just like how microservices replaced monolithic applications, SLMs are replacing monolithic language models in agent architectures.
The question isn't if you should adopt SLMs, but when and how fast you can implement them.
Connect and Learn More 🤝
Want to dive deeper?
- 🚀 Join our community: Collabnix Slack (10K+ developers)
- 📝 Follow me: @ajeetsraina for daily AI updates
- ⭐ Star our repos: DockerLabs | KubeTools
- 📚 Read more: ajeetraina.com for hands-on tutorials
🚀



