🔍 From Prompt Engineering to Context Engineering

The shift from prompt engineering to context engineering reflects a broader evolution in how we design, manage, and optimize interactions with large language models (LLMs). While prompt engineering was once hailed as a core skill for leveraging LLMs, the future lies in how we structure and engineer the context in which these models operate.
Prompt Engineering: The Starting Point
Prompt engineering emerged as a practical approach to crafting effective inputs for LLMs. It includes:
- Using specific phrasing (e.g., “You are an expert lawyer…”).
- Giving examples in a few-shot or zero-shot format.
- Adding instructions like “Think step-by-step.”
This helped maximize LLM performance without retraining or fine-tuning.
Limitation: Prompt engineering focuses on static strings and does not scale well to complex workflows, multi-turn conversations, or large corpora.
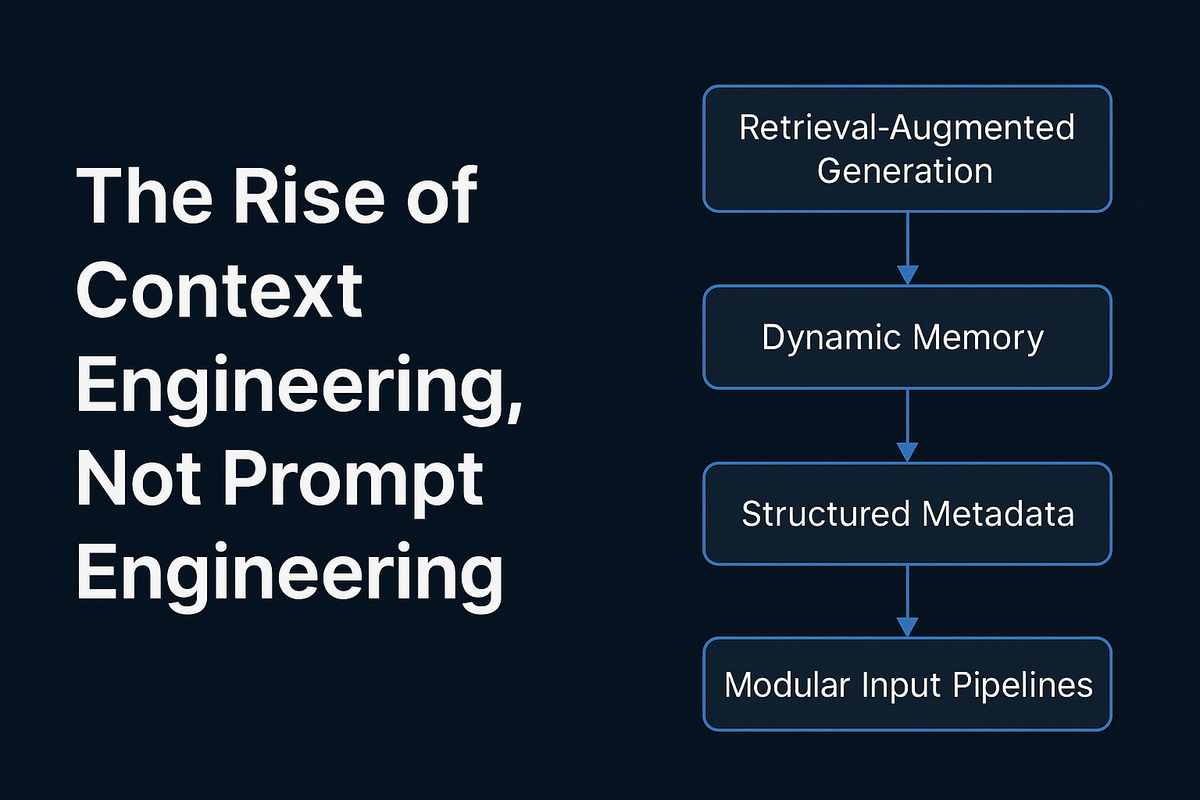
🧠 Context Engineering: The Next Evolution
Context engineering is about designing the entire environment around the model, including:
- Retrieval-Augmented Generation (RAG) pipelines.
- Dynamic memory and state management.
- Structured metadata injection (e.g., user identity, roles, conversation history).
- Modular input pipelines combining vector databases, APIs, and real-time data.
Why It Matters:
- LLMs are stateless: They don’t "remember" things unless you reinsert that memory into their context window.
- LLMs hallucinate: Contextual grounding through external data retrieval reduces this.
- LLMs are brittle: Prompt-only approaches don't scale or generalize across use cases.
📦 What Does Context Engineering Involve?
| Component | Description |
|---|---|
| RAG Systems | Combine LLMs with external data sources (e.g., documents, databases) to answer based on fresh or private data. |
| Orchestration Layers | Tools like LangChain, LlamaIndex, or custom pipelines to dynamically build the context window per request. |
| Memory Architectures | Implement short-term and long-term memory (e.g., using Redis, vector stores, time decay mechanisms). |
| Task-Aware Context | Inject role, intent, and goals of the user—critical for agents and copilots. |
| Observation & Feedback | Logging model responses, user feedback, and context to fine-tune pipelines and improve quality over time. |
⚙️ Tools Empowering Context Engineering
- Vector DBs: Pinecone, Weaviate, Chroma, Qdrant.
- Frameworks: LangChain, LlamaIndex, Haystack.
- Embeddings: OpenAI, Cohere, Hugging Face Sentence Transformers.
- Monitoring: Traceloop, Arize, PromptLayer, Langfuse.
💡 Real-World Use Cases
- Customer Support Agents
- Retrieve personalized history, product docs, and policies dynamically.
- Coding Assistants
- Pull API references, repository info, and coding conventions in real-time.
- Enterprise Chatbots
- Serve answers grounded in a company’s private knowledge base.
- AI Observability Tools
- Analyze the context pipeline, not just the prompt or response.
🔮 Future Outlook
- Context engineering will become a core software engineering practice—akin to backend, frontend, or DevOps.
- Model-specific prompts will become a minor detail in a more holistic AI application pipeline.
- Expect to see roles like "Context Architect", "LLM Orchestration Engineer", or "AI Product Designer".