
Connecting to Your NVIDIA Jetson AGX Thor via Type C cable on macOS
No monitor? No problem. Learn how a simple USB Type-C charging cable and serial console access saved a student demo at our Docker meetup.
No monitor? No problem. Learn how a simple USB Type-C charging cable and serial console access saved a student demo at our Docker meetup.
What if your AI chatbot could configure itself based on what customers ask, without developers editing config files? That's Dynamic MCP.

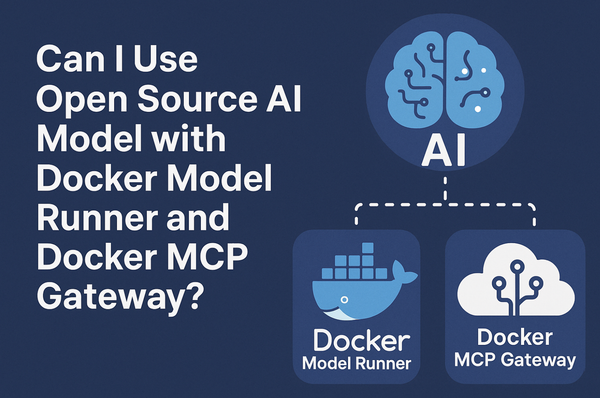
Want to add vision capabilities to your applications without sending data to external APIs? Docker Model Runner makes it straightforward to run multimodal AI models locally, giving you complete control over your data while using the familiar OpenAI-compatible API format.
Docker
This guide walks you through connecting models from the Docker AI Model Catalog to MCP servers, enabling your applications to leverage both local inference and external capabilities in a secure, reproducible Docker Compose environment.

Stop wasting hours setting up MCP servers. The Docker MCP Catalog provides 270+ enterprise-grade, containerized Model Context Protocol servers that install in seconds—no dependency hell, no environment conflicts, no cross-platform issues.
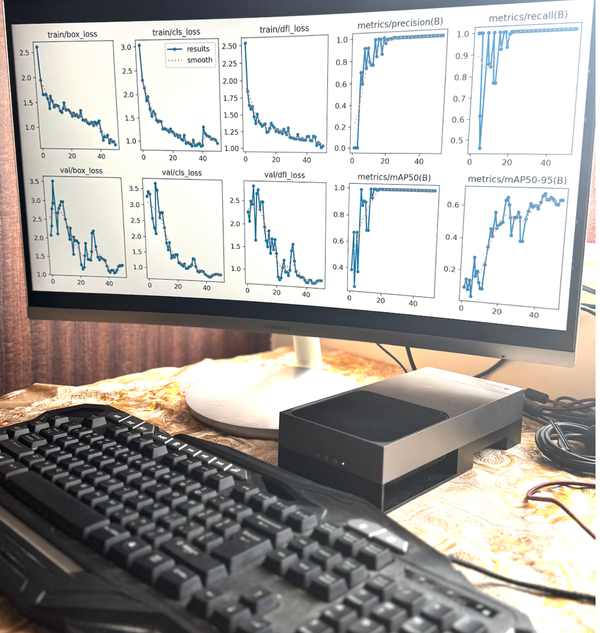
How we built, trained, and deployed a dental X-ray analysis system achieving 99.5% mAP50 accuracy using YOLOv8, Docker containers, and iterative model improvement using NVIDIA Jetson AGX Thor

If you're building robots, you're going to want to hear about this.

In this world of influencers, life is not easy. The pressure to stay visible, relevant, and knowledgeable is constant.

Docker Model Runner uses llama.cpp's KV cache for automatic token caching, eliminating redundant prompt processing in local LLM deployments. Discover how this built-in optimization works.
Designed to reduce vulnerabilities and simplify compliance, DHIs integrate easily into your existing Docker-based workflows as well as Kubernetes deployments with little to no retooling required.
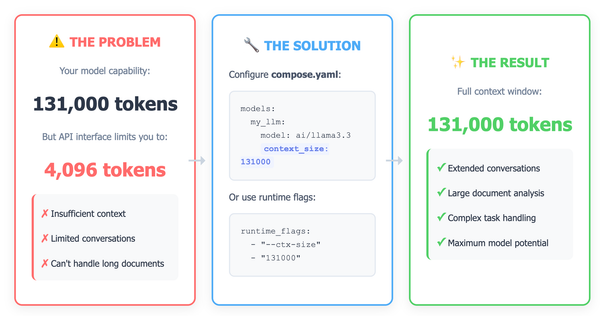
Frustrated by tiny context windows when you know your model can handle so much more? If you're running llama.cpp through Docker Model Runner and hitting that annoying 4096 token wall, there's a simple fix you need to know about. Your model isn't the problem—your configuration is.

Post-GITEX, 27 innovators gathered at Coders HQ for the Agentic AI and Security Meetup. The topic? "Agentic AI and Docker." But it was the questions that revealed the real story—engineers already deploying custom models, architects rethinking infrastructure for multi-LLM systems.