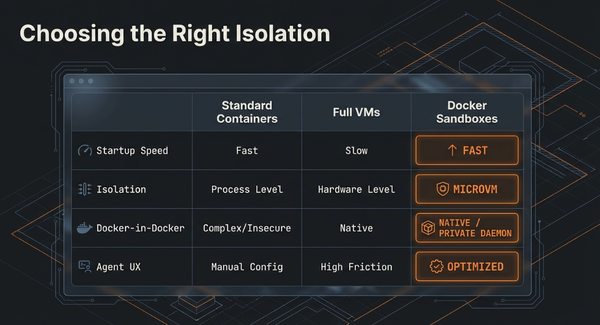
Understanding Quantization in AI
Quantization = compressing a model by lowering the precision of numbers, making it smaller, faster, and cheaper to run, often with only a small drop in accuracy.

Quantization in AI is the process of reducing the precision of numbers (the weights and sometimes activations in a neural network) to make models smaller and faster, while trying to keep accuracy close to the original.
Instead of storing every parameter as a 32-bit floating point number (FP32), we use fewer bits like 16 (FP16), 8 (INT8), or even 4 (INT4).
🔹 Why Quantize?
- Smaller Model Size
- Reduces storage and download size.
- Example: A 30B parameter model in FP32 would be ~120 GB, but INT4 quantization shrinks it to ~15 GB.
- Less Memory Usage
- Easier to fit on GPUs/CPUs with limited RAM/VRAM.
- Faster Inference
- Smaller numbers → fewer computations → faster response times.
- Lower Energy Costs
- Saves compute power, which is crucial for deploying AI at scale.
🔹 Types of Quantization
- Post-Training Quantization (PTQ)
- Quantize the model after training.
- Easy to apply but may slightly reduce accuracy.
- Quantization-Aware Training (QAT)
- Train the model while simulating quantization.
- Usually gives better accuracy at lower bit-widths.
- Dynamic vs Static Quantization
- Dynamic: Weights quantized, activations converted on-the-fly.
- Static: Both weights and activations quantized, usually faster.
🔹 Example:
Say you have a weight: 0.87654321 (32-bit float).
- FP32 → stores with full precision (4 bytes).
- FP16 → stores as 0.877 (2 bytes).
- INT8 → maps it to an integer scale, maybe 112 (1 byte).
- INT4 → super compressed, maybe stored as 9 (0.5 bytes).
The model still “understands” patterns, but with fewer bits of detail.
✅ In short: Quantization = compressing a model by lowering the precision of numbers, making it smaller, faster, and cheaper to run, often with only a small drop in accuracy.