Announcing Operational AI with Docker Book by Ajeet Singh Raina & Harsh Manvar
Operational AI with Docker Book is live today. 🎉


Get the Book
📘 Packt: Operational AI with Docker
📦 Amazon: Available now (paperback + Kindle)
🔖 ISBN: 9781807301095
For the better part of two years, I had a problem I couldn't solve in 280 characters or a blog post.
Every time I ran a Collabnix Meetup and we were running them often, with three or four hundred DevOps engineers and developers showing up each time, mostly new faces - someone would walk up to me afterwards and ask the same question:
"Ajeet, where do I start with Docker and AI?"
And honestly? My answer used to be a bit lame.
I was writing one almost every day. The landscape was shifting that fast. We were moving from what I think of as GenAI 1.0 to 2.0 - from chatbots to automated AI workflows. MCP had just emerged. Docker Model Runner was new. Sandboxes hadn't even shipped yet. There was massive confusion about where to even begin.
Then came December 2024. MCP was introduced, and within a few weeks the ecosystem had over 3,000 MCP servers. That's when it really hit me: blog posts aren't enough anymore. People need a single, structured place to learn this end to end.
So Harsh Manvar and I decided to write the book.
Today, when someone walks up to me at a meetup and asks where to start with Docker and AI, I can finally say with confidence: go grab this book. You can learn it from scratch.
It's called Operational AI with Docker, it's published by Packt, and as of today — it's live.
Why "Operational AI"?
I keep going back to 2013 to explain what we're trying to do with this book.
When Docker was introduced, the whole idea of build, ship, and run software became wildly popular. Suddenly, moving from monoliths to microservices wasn't a giant migration project - it was something a developer could actually do on a Tuesday afternoon. The way I describe it: it was like ordering an iPhone from Amazon. You unbox it, switch it on, and it just works. No "CPU unsupported" errors. No dependency hell. No "works on my machine."
Docker solved that exact problem for software workloads.
AI today has the exact same packaging problem - just with heavier baggage. Models, weights, tokenizers, GPU drivers, fragile Python environments, agents that need tools, tools that need secrets, secrets that need policies.
So Docker is doing for AI what it did for software a decade ago. The same three-word story, extended:
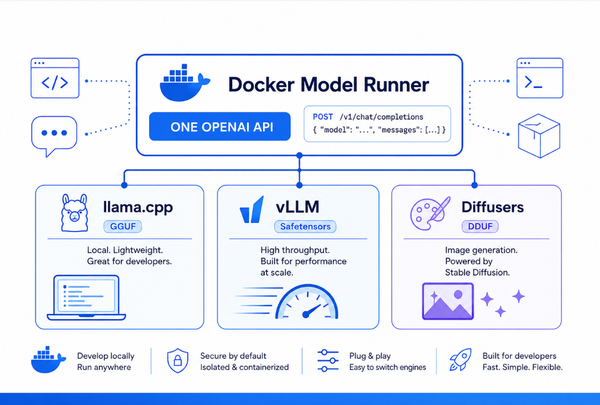
- Build AI agents using the MCP Toolkit, the MCP Catalog, and Docker Model Runner.
- Ship them with Agentic Compose and Docker Agents.
- Run them inside Docker Sandboxes.
The philosophy hasn't changed. Build, ship, run — extended to AI workloads. That's the entire thesis of this book.
Docker isn't trying to be an AI framework. It's the runtime and packaging layer underneath, so the AI parts can actually be portable, reproducible, and shippable. That's where Docker fits. That's what this book teaches you to do.
The Real Problems This Book Solves
When teams come to me asking about Docker and AI, they usually think their problem is technical. Most of the time, it isn't. Here are the four challenges I see over and over, and the book tackles each of them head-on:
1. Choosing the right model
Hugging Face today has more than two million AI models on it. Two million. So when a team starts an AI project, the first thing they hit isn't a Docker problem — it's a decision problem.
In Chapter 6, I break this down with a diagram, splitting models into three buckets:
- Small Language Models (SLMs) — roughly 0 to 7 billion parameters
- Medium Language Models — the middle range
- Large Language Models — the 70-billion-plus class
Most teams don't need an LLM. They need an SLM that runs cheaply, fast, and close to the user. But figuring that out takes effort, and very few people do it before they start coding.
2. The "AI = cloud-only" perception trap
Most developers, when they hear "AI model," immediately think OpenAI, Gemini, Claude — something that lives in the cloud, behind an API key, costing money per token.
That assumption shapes the entire architecture before anyone has written a line of code. The book breaks that assumption open and shows you what local-first AI actually looks like in practice.
3. GPU fear
The moment you say "run a model locally," people panic about hardware. "Do I need a beefy GPU? Will my MacBook even handle this?"
There are great open-source tools out there — llmfit literally scans your hardware and tells you which models will run well on your machine, and it supports Docker Model Runner as a runtime. But most developers don't know these tools exist, so they default to the cloud out of fear, not necessity. The book walks through this so you can make the call with data, not anxiety.
4. "Should I even run my model inside a container?"
This is the question I get more than any other. And there's a real gap in understanding here.
With Docker Model Runner, you don't actually have to wrap the model in a container at all. DMR runs the model natively on the host, uses the GPU directly, and exposes it through an OpenAI-compatible endpoint — but it gives you Docker's packaging, versioning, and pull experience on top of that. You get the best of both worlds.
That nuance is missed by a lot of teams, and it's exactly the kind of thing the book unpacks early on.
What You'll Learn
The book is structured around the real lifecycle of an AI workload — from running a model on your laptop, to building agents, to securing and scaling them in production:
- ✅ Run LLMs locally with Docker Model Runner — pull a model the same way you pull a container image, with OpenAI- and Anthropic-compatible APIs.
- ✅ Build and secure AI agents with Docker MCP Gateway — the piece I think is most underrated in the current AI ecosystem. Dynamic tool discovery, policy enforcement, secrets isolation, audit logs.
- ✅ Orchestrate multi-agent workflows declaratively — defining agents, sub-agents, and tools in YAML using Docker Agent. Versioned, reproducible, reviewable.
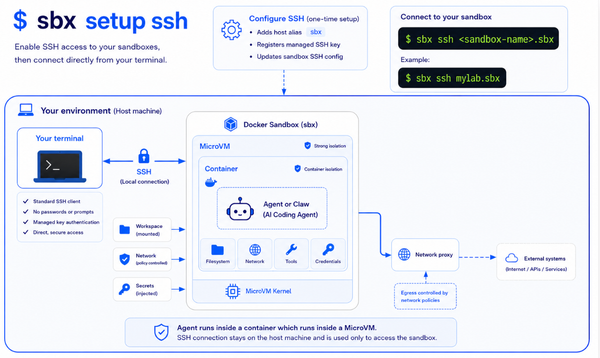
- ✅ Isolate agent execution with Docker Sandboxes — running untrusted, agent-generated code inside microVMs so a hallucinated
rm -rfnever reaches your host. - ✅ Build, run, and share multi-agent systems using Docker Agents — orchestrator-worker patterns, agent-to-agent communication, shared state, and when not to reach for multi-agent.
- ✅ Deploy and scale GenAI services on Kubernetes — taking everything from your laptop to a cluster, with the observability and cost-routing patterns production demands.
Built for developers. Grounded in real tools. No fluff.
Who Should Read It
Back in 2023, Harsh and I co-wrote a Docker blog called *"LLM Everywhere: Docker for Local and Hugging Face Hosting."* It went deep into model quantization formats — GPTQ, GGML — and how to actually run these models locally in containers. That blog took off. From an SEO standpoint, it became one of Docker's biggest hits in the AI space.
But what really shaped the audience for this book was the questions that came pouring in afterwards. People wanted to understand model training, model quantization, the trade-offs between formats. And one question came up over and over: "Should I even run a model inside a container?"
That tells you exactly where people are. They're not AI researchers. They're not pure ML engineers. They're developers, DevOps folks, and platform teams who suddenly need to make AI work in their existing world.
So that's who we wrote for:
- If you're a developer who built an agent demo and is now being asked to "productionize it" — this book is for you.
- If you're a platform engineer whose team is shipping LLM-powered services and you're trying to figure out the runtime story — this book is for you.
- If you're an architect mapping out an agentic AI strategy and need a concrete reference for what the operational layer actually looks like — this book is for you.
We didn't assume a deep ML background. If you know containers and you're curious about AI, you're in the right place. And if you know AI but containers feel like a black box, the early chapters meet you there.
Thank You
To Harsh Manvar — Docker Captain, Google Developer Expert, CNCF Ambassador, and the steadiest co-author I could have asked for. Our collaboration goes back years of Docker community blogs, and this book is the natural culmination of that.
To Apramit Bhattacharya, Preet Ahuja and the Packt editorial team — for pushing back on chapters I thought were finished, and for making the book sharper at every pass.
To the Collabnix community — 17,000+ of you across Slack and Discord — who have been the sounding board for every idea in this book, often without realizing it. Every meetup question, every late-night DM, every "Ajeet, but how does this actually work in production?" — those shaped this book more than anything else.
And to my family, who put up with a year of evenings and weekends.
If you pick it up, I'd genuinely love to hear what you think. Tag me on LinkedIn or X (@ajeetsraina), drop into the Collabnix Slack, or just reach out directly. The companion code is open source, and we'll be maintaining it as the Docker AI stack continues to evolve.
Operational AI is not a finished problem. This book is a snapshot of where the practice stands in 2026 — and a foundation you can build on as it keeps changing.
Let's keep figuring it out, together.
— Ajeet