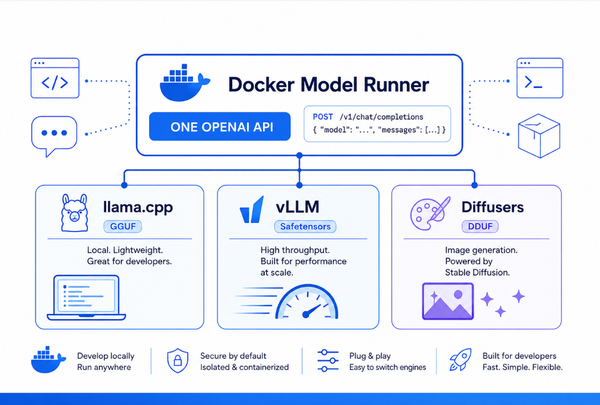
How Docker Is Solving the AI Governance Problem
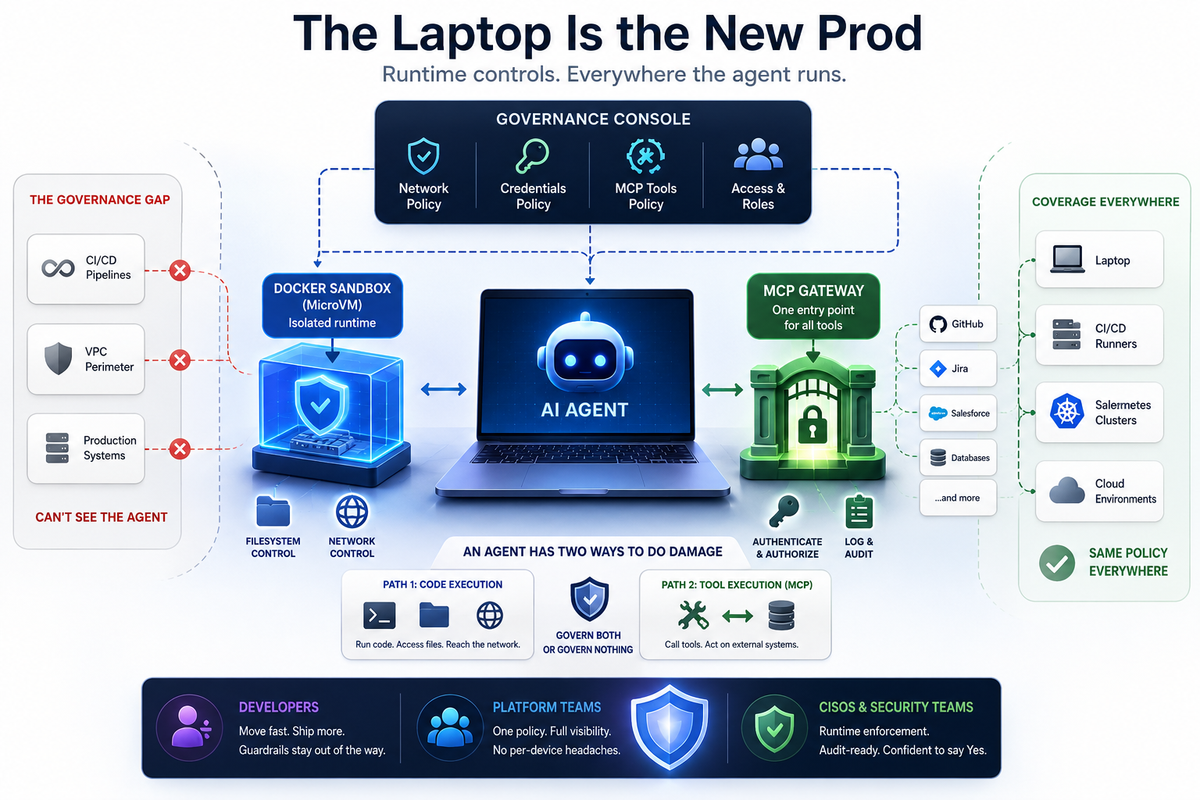
The Laptop is the New Prod

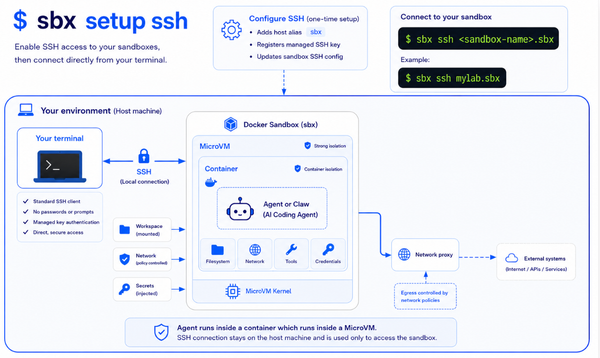
Here‘s an open question for you ~ In 2026, where does the most powerful, least governed compute in your enterprise actually live?
Not in your data center. Not behind your CI/CD pipeline. Not inside your VPC.
It lives on a developer’s laptop, running an agent, authenticated as that developer, reaching into private repos, production APIs, customer records, and the open internet, often all in the same session.
That is the AI governance problem in one sentence. And it is the reason most of the governance conversation happening in boardrooms right now is aimed at the wrong target.
The gap nobody planned for
The numbers tell the story plainly. Roughly 60% of organizations already have AI agents in production. And about 40% point to security and compliance as the single biggest barrier to scaling them further.
Read those two figures together. Adoption has already happened. Governance has not. That space between “it’s running” and “we control it” is exactly where the risk lives.
Agents stopped being autocomplete a while ago. Developers now use them to read entire codebases, refactor across services, and ship whole features end to end. The same shift is moving through finance, sales, support, and marketing, where a new class of agents is already sending emails, pulling CRM data, reconciling reports, and querying production systems.
The productivity gain is too large to refuse. So nobody is refusing it. They are just running it without a net.
Why your existing tools are blind to this
The instinct in most enterprises is to reach for the controls already on the shelf. That instinct fails here, and it fails for a structural reason.
→ CI/CD does not see the agent, because the agent is not a pipeline.
→ The VPC does not see the agent, because the laptop sits outside the perimeter.
→ IAM does not see the agent, because the agent is acting as the developer.
Two decades of hardening went into systems the agent simply walks around. So the CISO cannot answer the three questions that matter: what did the agent touch, what did it run, and where did the data go. And they cannot tell the business to slow down either, because the productivity is real.
That is the bind. The honest version of most “AI governance policies” written today is a PDF that the runtime never reads.
Strip it to first principles
When I am trying to validate whether a security claim actually holds, I find it useful to reduce the threat to its smallest shape. An agent has exactly two ways to do real damage.
→ It executes code itself, touching files and opening network connections.
→ It calls a tool through an MCP server to act on some external system.
That is the whole surface. Govern both paths and you have governed the agent. Miss either one and you have governed nothing, you have just documented your intentions.
This gives you a clean test for any AI governance solution, and it has two parts.
First, the controls have to live at the runtime layer where the agent actually executes. Not as advisory rules sitting on top that a sufficiently clever prompt can route around. Advisory governance is theater. The agent has to be physically unable to do the thing, not politely asked not to.
Second, the controls have to follow the agent. Agents do not stay on the laptop. They migrate to CI runners, to staging clusters, to production. A policy that only holds in one of those places is not a policy, it is a gap with a start date.
Why Docker is structurally positioned to solve this
Here is the part that I think is underappreciated, and it is less about features than about substrate.
Docker owns the layer the agent is running on. That single fact changes what governance can be.
→ The first path, code execution, gets contained by the sandbox. Every agent session runs inside a microVM-based isolated environment where filesystem and network access are bounded by a hard wall. Enforcement happens at the level of the process, not as a suggestion. This is the difference between a fence and a sign that says “please do not cross.”
→ The second path, tool calls, gets contained by the MCP Gateway. Every call routes through a single chokepoint where it can be authenticated, authorized, and logged before it ever reaches the external system. One door, watched.
Because these are runtime primitives rather than wrappers around someone else’s runtime, the enforcement is strict instead of advisory. The policy is not a layer on top of the thing that runs the agent. It is the thing that runs the agent.
And then the second test, portability, falls out almost for free. The same sandbox primitive runs on the laptop, inside Kubernetes, and across cloud environments, with the same policy model and the same guarantees. When the agent moves from a developer’s machine to a CI runner to a production cluster, the policy moves with it, because the runtime underneath is identical in all three places.
This is the claim no other category can make.
→ Endpoint security tools do not extend to clusters.
→ Cluster security tools do not reach the laptop.
→ Cloud security tools do not run on either.
Docker covers all three because Docker is what is executing the agent in all three. That is not a marketing position. It is just where the code runs.
What Docker AI Governance actually does
Sitting on top of those primitives is a control plane. From one admin console, security teams define and enforce policy across four surfaces: network, filesystem, credentials, and MCP tools. Defined once, enforced everywhere, no per-machine setup.
In practice that breaks down like this.
→ Sandbox policy for network and filesystem. Allow and deny rules for domains, IPs, and CIDRs, plus mount rules for filesystem paths scoped read-only or read-write. Only approved endpoints are reachable. Only approved directories are mountable. Enforcement happens at the proxy and mount level.
→ Credential governance. An agent is dangerous in exact proportion to what it can authenticate as. So you control which tokens and secrets a session can see, scope them to the life of that session, and block exfiltration to unapproved destinations. Developers stop pasting tokens into prompts, and security stops guessing where those tokens ended up.
→ MCP tool governance. Org-wide managed policies decide which MCP servers and tools are available, with unapproved servers blocked by default. Every call flows through the same engine as everything else. No second surface to configure, no bypass route.
→ Role-based assignment. Security research reasonably needs broader tool access than finance does. Create policy groups, assign users through your existing IdP over SAML and SCIM, and layer team rules on top of org-wide guardrails that cannot be overridden.
→ Audit and visibility. Every policy evaluation emits a structured event: user identity, timestamp, session context, and the exact rule that fired. Logs export cleanly into the SIEM you already run. This is the evidence a CISO needs to approve agent usage at scale instead of tolerating it quietly.
→ Automatic propagation. A developer authenticates, their machine pulls the latest policy, and updates reach every device on their own. Define once, enforced everywhere, no chasing endpoints.
What this unlocks, and why it matters
The framing I keep coming back to is this: governance should be invisible, and autonomy should be real. Those two goals usually fight each other. Most security tooling buys safety by adding friction until developers route around it.
The interesting move here is putting the controls at the runtime instead of in the workflow. When the boundary is the microVM and the chokepoint is the gateway, the developer does not feel the policy. They just get an agent that physically cannot wander outside its lane.
→ CISOs get the layer they have been missing, and the confidence to say yes instead of no.
→ Platform teams get one policy to define and full auditability, instead of a per-machine rollout nightmare.
→ Developers get the speed agents promised, with guardrails that stay out of the way.
The practitioner’s takeaway
If you take one thing from this, make it the test, not the product.
Any AI governance approach you evaluate this year should answer two questions. Does it enforce at the runtime where the agent actually executes, or does it just advise? And does the same policy hold when the agent moves from the laptop to the cluster to the cloud, or does it leak at the seams?
Most answers fail one of those. The reason Docker can pass both is not clever engineering layered on at the end. It is that the governance and the runtime are the same object.
We spent two decades learning to treat prod like prod: locked down, audited, governed. The laptop just became prod. It is time we governed it that way.
Want to see how the controls behave in practice? The honest way to evaluate any of this is to run an agent against a real policy and watch what it can and cannot reach. That is a follow-up post worth writing.