How Autonomous AI Agents Become Secure by Design With Docker Sandboxes
AI coding agents are incredibly useful until you realize they're running next to your SSH keys and AWS credentials. Here's how Docker Sandboxes changes that.


I've been running AI coding agents for a while now. Claude Code on my MacBook, pointed at a project directory, autonomously editing files, running tests, pushing commits. It's genuinely useful ~ the kind of useful that makes you wonder how you shipped code without it.
But a few months ago I started asking myself a question I'd been quietly avoiding: what exactly can this agent reach while it's running?
The answer, once I actually looked, was uncomfortable. Everything. It could reach everything I could reach my SSH keys, my AWS credentials, my .env files, my Git tokens. Not because it was malicious. Just because it was running on my laptop, as me, with my permissions.
That's when Docker Sandboxes (sbx) started making a lot more sense to me. I wrote about sandboxing my AI coding agent for the first time a couple of months back — this post goes deeper, walking through the full governance Labspace we built and why structural isolation is the only honest answer to the agent security problem.

The Uncomfortable Truth About Agents on the Host
Here's the pattern most teams are using today, including me until recently:
export ANTHROPIC_API_KEY=sk-ant-...
claude .
Simple. It works. The agent reads your codebase, understands context, makes changes. Developers love it and for good reason.
The problem is what else is sitting on that same machine:
~/.ssh/id_rsa # your private SSH key
~/.aws/credentials # full AWS access
~/.config/gcloud/ # GCP credentials
~/.kube/config # Kubernetes cluster access
.env # database passwords, API keys, secrets
The agent didn't ask for access to any of that. You didn't grant it. But it's there, in the same filesystem, readable by the same process. I call this the YOLO pattern — and it describes the vast majority of agentic AI setups in production today.
The risk isn't that your agent is malicious. It's that agents are increasingly reading external content ~ READMEs, web pages, GitHub issues, pull request descriptions. Any of that content could contain a prompt injection that redirects the agent's behavior. A cleverly crafted README can instruct your agent to exfiltrate credentials to an external endpoint, and the agent will try to be helpful.
You don't need a sophisticated attack. You just need an agent that's trying to do its job.
What "Blast Radius" Actually Means
Before jumping to the solution, I want to spend a moment on the concept of blast radius ~ the total surface area of damage if something goes wrong.
When an agent runs on the host, the blast radius is enormous:
| What the agent can reach | What that enables |
|---|---|
| SSH keys | Push to any server you have access to |
| Cloud credentials | Provision infrastructure, access data, rack up bills |
| Git tokens | Push to any repository you can write to |
.git/hooks/ in your project |
Install code that runs every time you git commit |
.github/workflows/ |
Modify CI pipelines that execute on every push |
/etc/hosts |
Read your internal network topology |
The git hooks one is particularly sneaky. An agent modifying .git/hooks/pre-commit can install persistence that outlives the agent session itself. The microVM protects you while the agent is running — but anything written to your workspace directory stays there afterward. That's why the Labspace we built has a dedicated section on reviewing agent changes before you act on them.
The core question isn't whether you trust your agent. It's whether you trust every piece of content your agent will ever read. For me, the honest answer is: not entirely.
A Different Approach: Structural Isolation
The standard response to agent security concerns is policy. Add guardrails. Improve the system prompt. Monitor the output. Red-team the agent. These things have value, but they share a common weakness: they rely on the agent choosing to stay within bounds.
A well-crafted prompt injection can bypass any instruction. An edge case in the agent's reasoning can send it somewhere unexpected. Policy is better than nothing, but it's operating at the wrong layer.
Docker Sandboxes takes a different approach entirely. Instead of asking the agent to behave, it structurally removes the things the agent shouldn't be able to reach.
# Same agent. Same task. Different architecture.
sbx run claude .
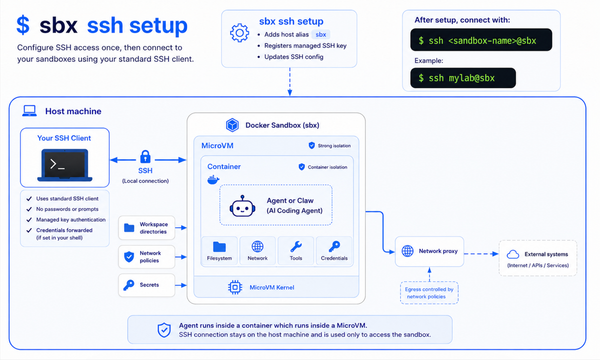
That one change puts the agent inside a microVM — a lightweight virtual machine with its own Linux kernel, its own Docker Engine, and its own network namespace. The only filesystem path shared between the VM and your host is your project directory. Nothing else exists inside the sandbox.
Here's what that looks like in practice. Run this inside a sandbox:
sbx run bash -c 'ls ~/.ssh/ 2>&1; ls ~/.aws/ 2>&1; env | grep -i token 2>&1'
ls: cannot access '/home/user/.ssh/': No such file or directory
ls: cannot access '/home/user/.aws/': No such file or directory
The files aren't hidden. They don't exist. There's nothing to exfiltrate, no credential to steal, no SSH key to abuse. The blast radius just collapsed from "everything on your machine" to "whatever is in your project directory."
The architecture looks like this:
Your Mac / Linux host
└── Docker Desktop VM (or native on Linux)
└── Cloud Hypervisor microVM ← hardware boundary
├── Private Docker Engine
├── Claude Code process
└── ~/your-project (mounted read-write)
The boundary is hardware-level. Not a process boundary. Not a namespace you can escape with the right syscall. A hypervisor boundary — the same class of isolation that cloud providers use to separate customer workloads.
The Full Governance Stack
Isolation is the foundation, but the Labspace covers quite a bit more than just "agent in a VM." Here's what we built hands-on labs for.
Secrets Without Exposure
The obvious question once you see the isolation: if the agent can't see my AWS credentials, how does it actually authenticate?
Docker Sandboxes has a credential proxy for this. You register secrets with sbx, and the agent gets a runtime token it can use to make authenticated calls — but it can never read the underlying credential value.
sbx secret set AWS_ACCESS_KEY_ID
sbx secret set AWS_SECRET_ACCESS_KEY
sbx run claude .
The agent inside can call AWS APIs. It cannot read AWS_ACCESS_KEY_ID. It cannot pass that value anywhere. The proxy intermediates every use and enforces scope to the session. Least privilege, applied structurally rather than by policy.
Network Policy
By default, a sandbox in Balanced mode allows outbound internet access but blocks the host network and internal corporate network. For most development work, that's the right tradeoff. But you can be more specific:
# Lock it down to only what the agent actually needs
sbx policy ls
sbx policy deny network "*"
sbx policy allow network "github.com:443"
sbx policy allow network "files.pythonhosted.org:443"
# Or use Locked Down mode for air-gapped environments
sbx run --network locked-down claude .
Three modes to know:
| Mode | What it allows | When to use it |
|---|---|---|
| Open | Unrestricted outbound | Development agents that need full internet |
| Balanced (default) | Internet yes, host network no | Most day-to-day work |
| Locked Down | Explicit allowlist only | Enterprise, regulated, or air-gapped environments |
Every connection attempt ~ allowed or denied gets logged. For an enterprise or regulated environment, this is what answers the auditor question: what exactly did the agent communicate with, and when?
Branch Mode
This one has become my personal favourite. When you run an agent in branch mode, it works on an isolated copy of your repository. Its changes land on a new branch inside the sandbox. Your working tree is completely untouched.
sbx run --branch feature/add-tests claude -p "Add unit tests for the auth module"
# See what the agent actually did
sbx branch diff
# Only merge it if you're happy
sbx branch merge
It's the pull request review model, enforced at the infrastructure level. The agent can't accidentally push to main. It can't stomp on your in-progress work. You stay in control of when — and whether — the agent's output becomes part of your codebase.
Parallel Agents
The last section of the Labspace is about running multiple agents simultaneously, each in their own sandbox:
sbx run --name agent-tests claude -p "Write tests for the payment module" &
sbx run --name agent-docs claude -p "Update API documentation" &
sbx run --name agent-lint claude -p "Fix all linting errors" &
wait
# Review each independently
sbx branch diff --name agent-tests
sbx branch diff --name agent-docs
sbx branch diff --name agent-lint
Each one has its own microVM, its own branch, its own credential proxy session. They can't interfere with each other, no race conditions, no shared state, no cross-contamination between tasks.
This is where the security story becomes a productivity story. The isolation isn't slowing anything down — it's what makes it safe to run agents at scale without worrying about what they might step on.
From Trusting Agents to Not Needing To
There's a mindset shift in all of this that I find genuinely interesting.
The conventional approach to agent safety is about building better agents ~ agents you can trust more. Better reasoning, better guardrails, more extensive red-teaming. That's valuable work, and I'm not dismissing it.
But Docker Sandboxes is asking a different question: what if we could build an environment where the agent's trustworthiness is largely beside the point?
You don't trust your web application to avoid escaping its container. You design the container so escape isn't possible. The application can be perfectly written or full of bugs either way, the blast radius is bounded by the container boundaries, not by the application's good judgment.
The same idea now applies to AI agents. An agent in a microVM can be confused, manipulated, or just wrong and the consequences are still bounded to the project directory, the explicitly granted network access, and the scoped credentials. The structural boundary is doing the work that we've been asking the agent to do.
Try It Yourself
The full Labspace is at https://github.com/ajeetraina/labspace-sbx. Nine sections, all hands-on, with checkpoints that ask you to prove the guarantees to yourself ~ not just read about them.
# Install Docker Desktop 4.40+ (macOS/Windows)
# or the sbx binary directly (Linux/cloud)
# Verify it's working
docker sandbox version # macOS/Windows with Docker Desktop
sbx version # Linux
# Clone and start
git clone https://github.com/ajeetraina/labspace-sbx
cd labspace-sbx
The isolation proof section is worth doing at least once. Run the same credential enumeration commands outside and inside a sandbox, and watch the difference firsthand. It makes the architecture click in a way that diagrams don't. If you want a broader reference while working through it, the Docker Sandboxes tutorial and cheatsheet covers the CLI commands you'll reach for most often.
For a deeper look at the sbx CLI specifically ~ install, auth, shell sandbox, port publishing, I documented the full experience in Stop Running Agents in Containers. Run Them in MicroVMs with Docker sbx.
What Comes Next
Individual sandbox sessions give you per-session governance. The natural next step is extending that to organisation-wide policy ~ a consistent ceiling on what any agent can do across an entire company, with a unified audit log across every session. Docker is working on exactly that. More details soon.
For now, if you're running AI agents in any serious capacity, this Labspace is worth an hour of your time. The security model is genuinely different from what most teams are doing, and understanding it changes how you think about what agentic AI can safely be asked to do.